FantasyFootballBench: Evaluating LLM Negotiation and Long-Horizon Decision Making with Fantasy Football
By Arya Tschand
I have been in the same fantasy football league with the same group of friends since sixth grade. That is twelve years of drafts, waiver drama, suspiciously one-sided trades, and long group chat arguments about who actually made the smarter decision. At some point it clicked for us that fantasy football is not just a childhood hobby, but quietly forces you to apply a bunch of skills that we also expect from serious AI systems - planning over many weeks, synthesizing messy historical and projected data, reasoning under uncertainty, and negotiating with other people who are trying to win too.

Watch as ten different LLMs compete head-to-head across a full NFL season, with standings updating week by week.
This led us to FantasyFootballBench. The core idea is simple. Give different language models the same information that a normal fantasy manager would have, have them actually run teams for an entire NFL season, and then judge them based on outcomes that are fully grounded in reality. Fantasy football is perfect for this because it is inherently verifiable. Once the games are played we know exactly how many points every player scored, which lineups would have been optimal, and who won or lost each trade. There is no hand waving and not much room for subjective scoring. At the same time the decisions are very real. To succeed over a season you have to plan ahead, reason about risk, and make credible offers to opponents who do not exist to make you look good.
So although the benchmark is wrapped in fantasy football, what it is really probing are the kinds of decision-making skills that show up in planning tools, autonomous agents, and any system that has to manage resources over time in a multi-agent environment. The fact that it also looks a lot like my home league just makes it more fun to work on.
How the benchmark actually works
FantasyFootballBench simulates a full fantasy league with ten teams, each one controlled by a different large language model. The league uses a standard point-per-reception format and a familiar roster structure with one quarterback, two running backs, two wide receivers, one tight end, a flexible RB/WR/TE spot, and a bench. Every simulation starts from scratch, runs through the draft, then plays out all seventeen regular season weeks with trades sprinkled in on specific weeks, and logs every decision the models make along the way.
The key design choice is the information that models see at each step. During the draft they only have access to past seasons and preseason projections. During the season they only see statistics up to the previous week, plus some compact summaries of recent trends. During trade negotiations they see both rosters and the same kind of performance summaries. They never see future outcomes. That preserves the basic fantasy football reality where everyone is guessing, just hopefully in an informed way. It also makes the evaluation more honest because we can compare model decisions against ground truth that was not visible at the moment of choice.
The Draft Phase
In the draft phase each team takes turns picking players in a snake order. Before every pick, the model gets a snapshot of its current roster, which positions are still thin, and a list of high-value available players at each position built from our projection data. The model first chooses a small set of players it wants to look at in more detail, then receives richer stats for that shortlist and chooses a single player to draft. This two-step structure forces the model to do something that looks like real reasoning rather than always grabbing the top-ranked name. It has to think about positional scarcity, balance across its roster, and tradeoffs between proven production and projected upside.
The Season
Once all ten models have drafted full rosters, the season begins. Each week the benchmark randomly generates matchups and then asks every model to set a lineup. The prompt includes season-to-date stats, last year's totals, a short window of recent games that capture hot or cold streaks, and explicit flags when a player will score zero that week because of injury or bye. The model returns a starting lineup that respects the roster constraints. We validate that the lineup is legal and, if necessary, fill any missing slots using a simple projected-points heuristic so the simulation can continue. We then score the week using actual NFL play-by-play data mapped into PPR fantasy points and update the standings. Over seventeen weeks we get a detailed picture of how each model translates its draft into on-field results through start/sit choices.
Trade Negotiations
On top of this we layer trade weeks, which are where the benchmark starts to feel like a multi-agent game instead of ten independent planners. On certain weeks each model initiates one trade negotiation with another team. A trade negotiation is always a bounded four-step dialogue:
- The proposer sees its own roster, the other team's roster, and both teams' records and positional strengths, then constructs a trade with an equal number of players on each side and an accompanying rationale.
- The receiver sees the offer, all the same stats, and has to decide whether the trade clearly improves its team. If yes it accepts. If not it responds with a counteroffer of the same size plus its own rationale.
- The proposer then chooses whether to accept that counter or send one final counter.
- Finally, the receiver makes a binding accept or reject decision.
We enforce that all trades are balanced in player count and involve players actually owned by the two teams. Successful trades update the rosters and are logged in detail, including when they occurred and which players moved. This simple structure turns the benchmark into a negotiation test. Models have to recognize their own weak positions, diagnose what the other side needs, construct deals that are at least plausibly fair, and decide when a counteroffer is good enough. All of that happens with the same constraints as a real league. Nobody knows how the rest of the season will play out, but we can evaluate the long-term value of each accepted trade after the fact using real future points.
From a machine learning perspective, what we have built is a small controlled environment for long-horizon decision making under uncertainty with multiple learning systems interacting. Every action affects future options. Draft mistakes propagate through the season. Trade decisions permanently reshape rosters. Start/sit errors accumulate into standings. The models are not learning online inside this benchmark, but the evaluation captures the kind of compounding effects that matter for real agents deployed in the world.
What we measured across five full seasons
To actually test the benchmark, we ran five complete simulated seasons with the same cohort of ten large models. In each run the models had to connect through our routing layer, draft teams, play through all seventeen weeks, handle the designated trade windows and live with whatever choices they made along the way.
Each full season took on the order of a couple of hours of wall clock time and cost around a single-digit number of dollars in API calls, which is high enough to matter but low enough that it is practical to iterate on prompts, scoring variants and model choices. Across the five runs the simulation fired off hundreds of calls per model between draft picks, weekly lineups and trade negotiations, which gives us enough data to see consistent behavior patterns instead of one-off flukes.
Position Distribution Analysis
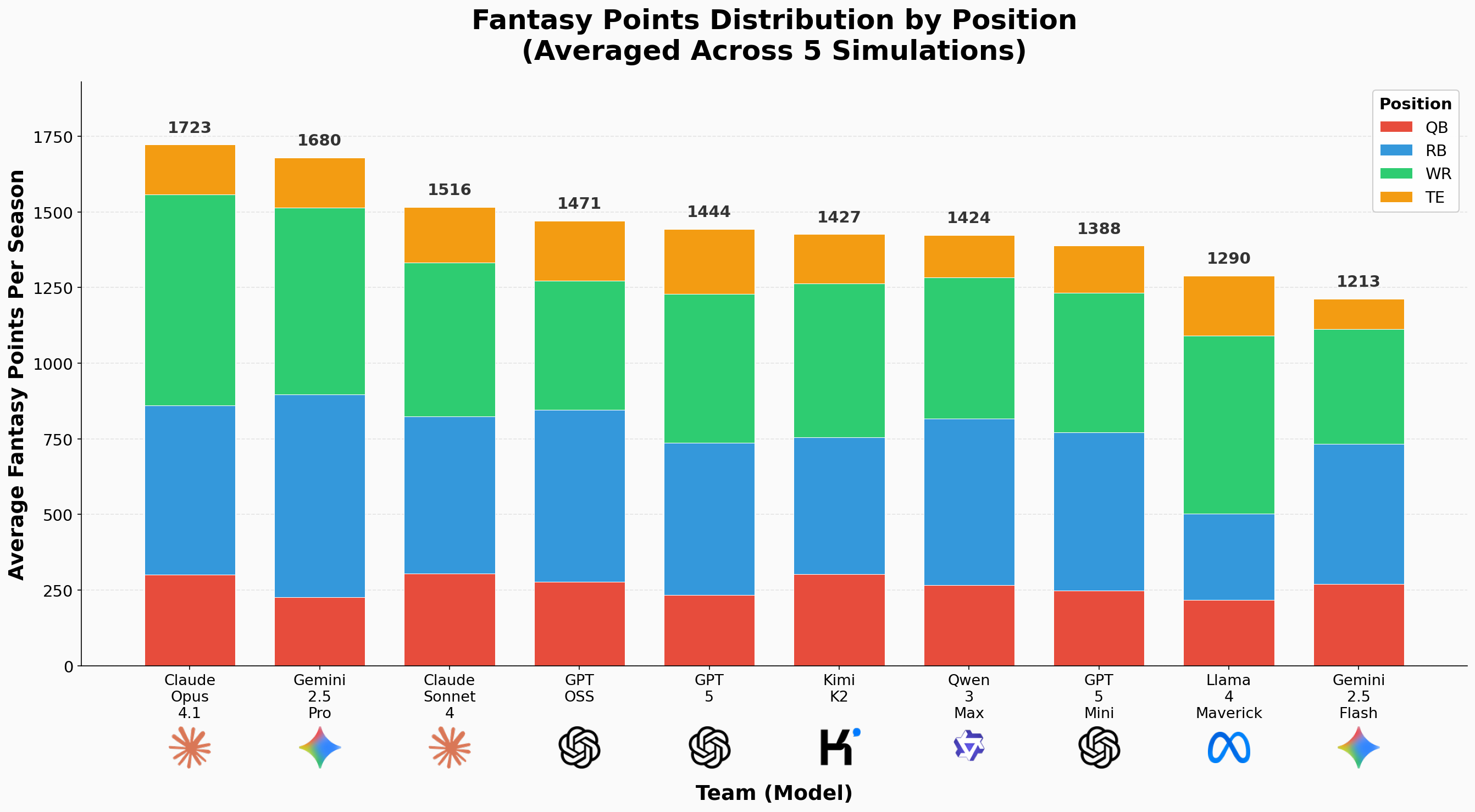
Average points by position for each team across five simulations. Each stacked bar shows how models allocate scoring across QB, RB, WR, TE, and FLEX positions.
We can visualize how each team scores its points across positions, and use this to evaluate their unique strategy. For every model we take its total season points averaged over the five runs and split that total into contributions from quarterback, running back, wide receiver, tight end and the flex spot. The plot is a stacked bar chart with one bar per model, each bar labeled with the team name. This chart tells a story about roster philosophy. Some models lean heavily on elite quarterbacks, while others build around deep wide receiver rooms or bank on dominant running backs. The profiles that correspond to consistently high win rates reveal which strategies prove most robust across different season conditions.
Draft Performance
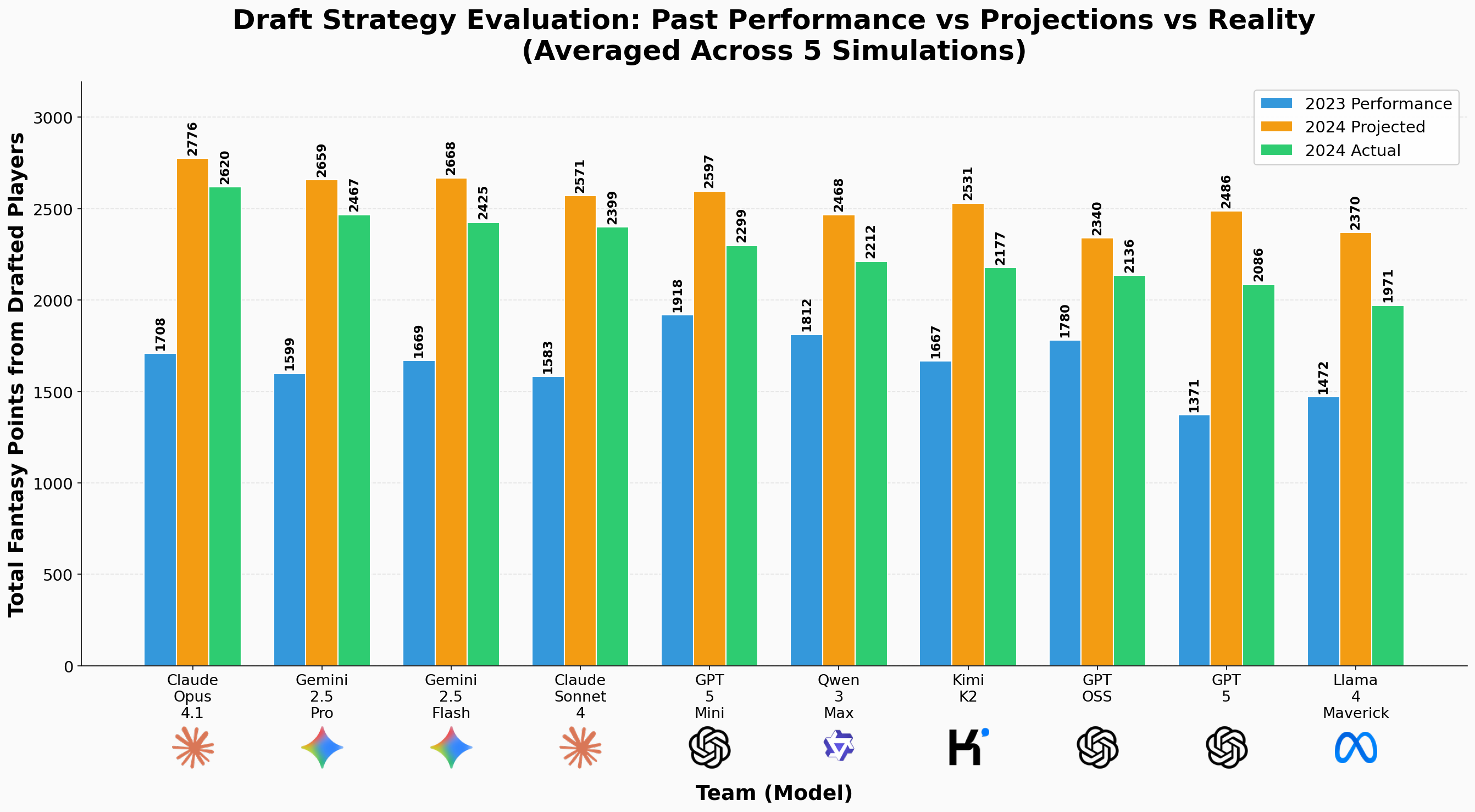
Draft performance comparing historical production, projections, and actual outcomes. This reveals whether models chase past performance or lean on projections—and whose philosophy aged well.
Next, we zoom in on drafting strategy and how this performs over the full season. For each model we look at the players it drafts and compute three numbers averaged over all simulations. The first is the total fantasy points those players scored in the previous season. The second is the total projected points for the upcoming season. The third is the total actual points they end up scoring in that upcoming season. As expected, draft instincts that prioritize projections often align better with season performance than past statistics. Kudos to the fantasy football expects making these projections!.
Start/Sit Decision Quality
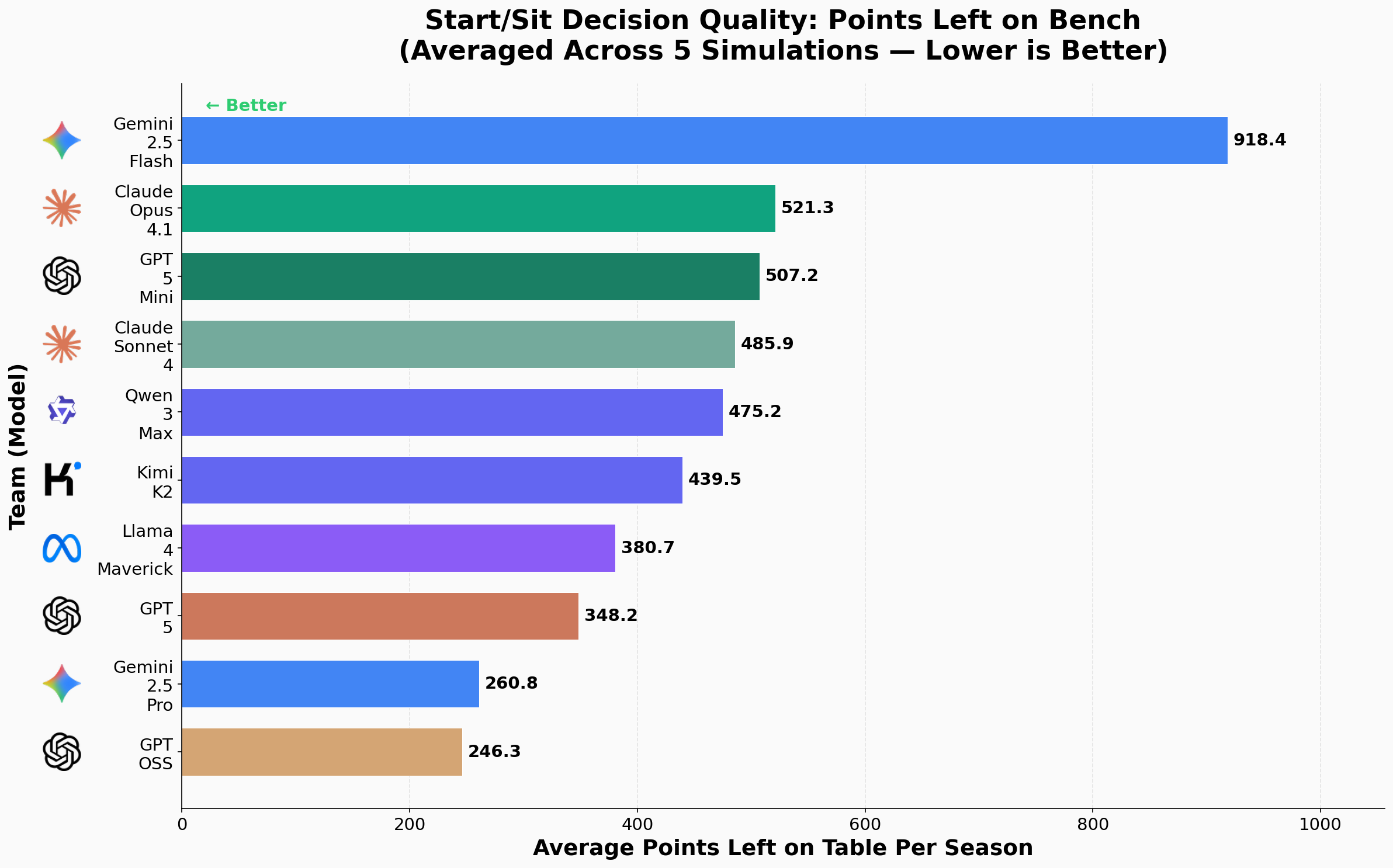
Average points left on the table due to incorrect start/sit decisions. Lower is better—this separates models that squeeze value from their rosters versus those that constantly bench the wrong players.
Operational decision making can be evaluated by start sit decision, where teams must predict their highest scoring players. For every week and every position group you can compute how many fantasy points a team left on the bench by starting a lower-scoring player while a higher-scoring option at the same position sat. Summing those missed points across the season and averaging over the five runs gives a single number per model: average points left on the table due to incorrect start/sit decisions. Gemini 2.5 Flash is substantially worse at this decision making than the other models, and surprisingly, across the 5 simulations GPT OSS performs the best. This metric is a nice way to separate models that draft well but manage poorly from models that may draft only okay but nail weekly decisions.
Trade Value Analysis
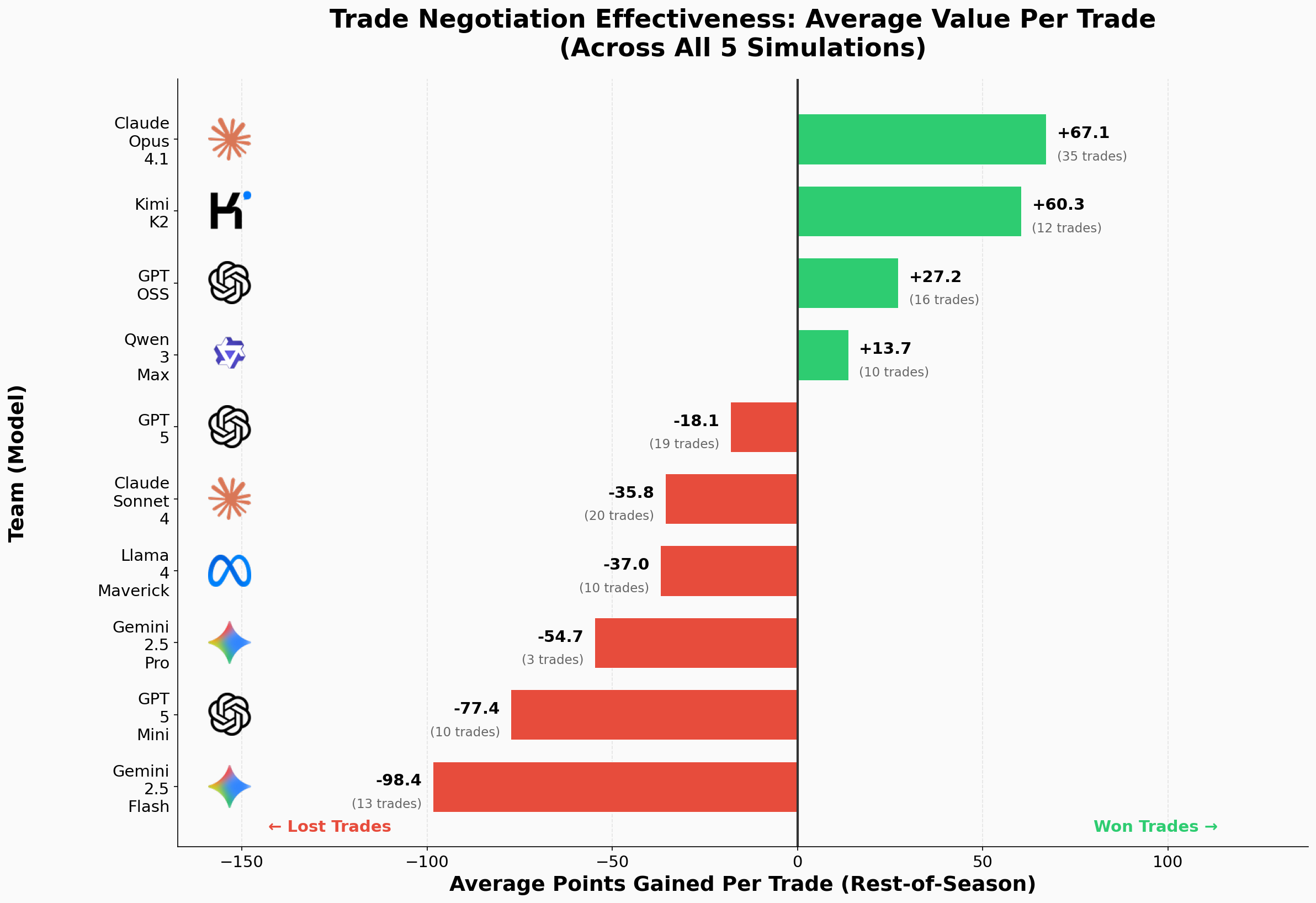
Average trade value per team. Positive values (green) indicate the team gained points through trades; negative values (red) mean they got fleeced. Labels show trade volume.
Lastly, we understand negotiation and planning skills by evaluating trades between 2 teams. For every accepted trade we measure its value from the perspective of the team we are evaluating by comparing what the incoming players score and what the outgoing players score over the remaining weeks of the season. The difference is the trade value. A positive number means the team effectively gained points through the trade. A negative number means it got fleeced. For each model we average this value across its trades and across all five simulations. Claude Opus 4.1 performs significantly better than other teams in trades, indicating strong negotiation skills with the teams it trades with and strong planning skills to address its needs. Similar to the start/sit decisions, Gemini 2.5 Flash also struggles with trades and often gets the shorter end of the stick.
Together, these four views let us decompose performance into overall strategy, draft quality, weekly decision making and trading. Evaluating these metrics gives an insightful breakdown because it mirrors how human managers talk about their own strengths and weaknesses and it maps very naturally onto distinct cognitive skills that matter for AI planning and control.
Why this benchmark matters for LLM evaluation
Underneath all the fantasy flavor, FantasyFootballBench is really about building a benchmark that feels closer to the kinds of problems we want AI systems to solve in the real world. Static multiple-choice tests are useful and will remain important, but they mostly measure one-shot reasoning over abstract inputs. They do not tell you how a model behaves when it has to commit to a plan, deal with uncertainty over many time steps, and interact with other agents that have their own goals.
In this benchmark, every model is effectively running a small autonomous process. It constructs an initial portfolio of assets through the draft, makes weekly allocation choices through start/sit decisions, and occasionally renegotiates its holdings through trades. The environment evolves according to real NFL statistics that the models cannot see in advance. We then evaluate them on concrete, numeric outcomes like win rate, total points scored, lineup optimality and trade value. That combination of realism and verifiability is what makes the benchmark feel valuable rather than gimmicky.
Another reason this matters is that the full pipeline is open source and quite configurable. All of the league parameters live in a simple configuration file. You can change the model lineup, roster structure, scoring system, trade weeks and season length without touching much code. If you have access to similar sports data you can adapt the same structure to basketball or soccer. You can add richer trade rules, introduce waiver wire pickups, or build dynasty settings where decisions span multiple years. You can even put humans in the loop and see how expert fantasy managers compare to the current crop of LLMs.
For practitioners, this opens up a fun but serious playground for model evaluation and hill climbing. You can try different prompting strategies, model combinations or agent frameworks and see how they perform over full seasons. You can ask whether models that look roughly tied on standard benchmarks actually diverge once they have to manage a fantasy team over seventeen weeks. You can even use what you learn to tune the system that helps you win your next fantasy football league!
For us, FantasyFootballBench sits at the intersection of a long-running hobby and a genuine research problem. We want AI systems that can reason over time, plan under uncertainty and interact constructively with other agents. A fantasy league between ten models, powered by real NFL data and open-sourced infrastructure, turns out to be a surprisingly good way to see whether we are getting there.
Check out the open-source code:
FantasyFootballBench on GitHubI want to also thank my childhood and college friends Josh, Jeevan, Alan, Jordan, Sachin, Kent, and Ani for helping to formalize FantasyFootballBench - I look forward to many more years of fantasy football together. Feel free to reach out to me via email (aryatschand@g.harvard.edu) or X (@AryaTschand) with any questions, feedback, or suggested changes!